논문 리뷰
DFX: A Low-latency Multi-FPGA Appliance for Accelerating Transformer-based Text Generation
By Seongmin Hong(KAIST), Seungjae Moon(KAIST), Junsoo Kim(KAIST), Sungjae Lee(NAVER), Minsub Kim(NAVER), Dongsoo Lee(NAVER), and Joo-Young Kim(KAIST)
I. Introduction
트랜스포머는 딥러닝 언어 모델로 인풋 데이터의 각 부분마다 중요도 가중치를 다르게 주는 어텐션 기법을 사용한다. 회귀와 RNN과 LSTM의 글로벌 디펜던시 문제를 해결하면서 사실상 텍스트 생성과 같은 자연어 처리의 표준 기법으로 자리 잡았다.
텍스트 생성 과정은 요약과 생성 단계로 나뉘는데, 언어 모델은 인풋 토큰으로부터 생성된 인풋 context를 이용하여 지속적으로 연속적인 아웃풋 토큰을 생성한다. 생성 단계는 각 iteration 마다 하나의 아웃풋 토큰을 생성하며 이전 단계의 아웃풋 토큰을 인풋으로 사용한다.
현재의 서버 플랫폼에서는 택스트 생성에 GPU를 사용하는데, GPU의 대량 병렬 계산 유닛은 인풋 토큰을 동시에 계산할 수 있게 하기 때문에 요약 단계에서 좋은 성능을 발휘한다. 그러나 Sequential Processing에는 맞지 않기 때문에 생성 단계에서는 성능이 저하된다.
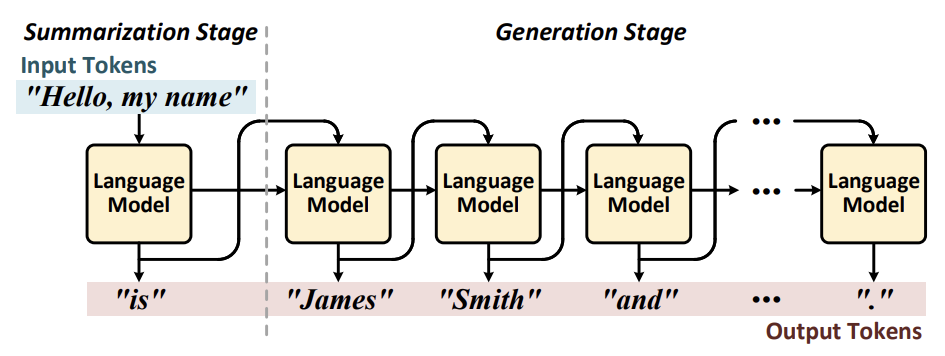
이 논문에서는 DFX라는 Multi-FPGA 가속기를 제안한다. Sequential Characteristic을 다루기 위해 DFX의 Compute Core는 단일 토큰 처리에 최적화 되어있다. 또한, 최대 HBM을 위해 GPT의 특성에 기반한 효과적인 Tiling Scheme과 dataflow를 사용한다. Model Parallelism으로 연산 코어 수를 늘리고 로드를 고르게 분배한다. 다른 언어 서비스로 확장할 수 있도록 FPGA 모델을 이용한다.
II. Background
A. GPT Language Model
트랜스포머는 인코더와 디코더 파트로 이루어져 있는데 각각 인풋과 아웃 시퀀스의 처리를 담당한다. 그러나 GPT는 텍스트 생성에 초점을 맞췄기 때문에 디코더만 가지고 있다. GPT가 인코더를 없앨 수 있었던 것은 인코더 대신 미리 훈련된 행렬을 사용하는 Token Embedding을 사용하기 때문이다. GPT의 모델 사이즈와 디코더 레이어 수는 더 높은 정확도를 위해 증가하고 있다. 이 논문은 GPT-2 모델 기반이지만 Size만 늘리면 GPT-3에도 적용이 가능하다는 점에 주목한다.
GPT-2 Structure
디코더의 시작 부분에 위치한 Token Embedding은 인풋 단어들을 임베딩 벡터로 변환한다. 인풋 단어들은 Dictionary에 기반하여 Token ID로 변환된다. Pre-trained Matrices와 Word Token Embedding (WTE), 그리고 Word Position Embedding (WPE)는 Token ID와 인덱싱 하여 대응되는 벡터를 얻는다. LM head는 디코더의 마지막 부분에 위치하며 아웃풋 임베딩 벡터를 Token ID로 변환한다. 이 과정은 WTE의 transpose와의 행렬 곱을 요구하며, softmax를 적용하여 가장 높은 확률을 가진 Token ID를 선택한다. 선택된 Token ID가 생성된 단어를 나타낸다.
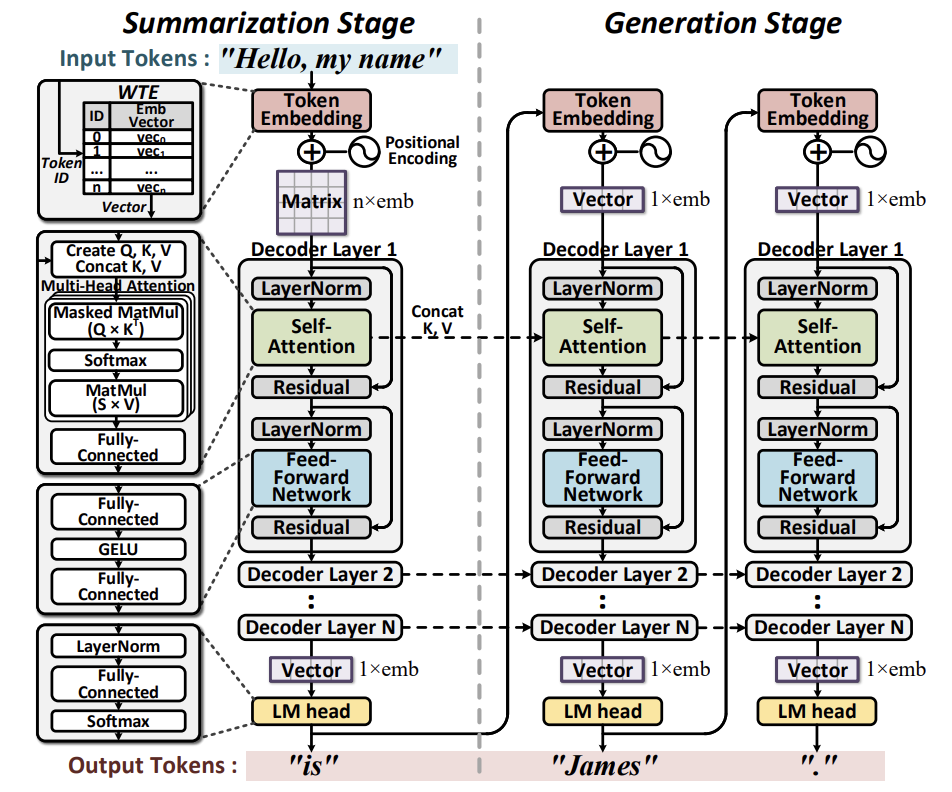
GPT-2는 Token Embedding과 LM head 사이에 N개의 디코더 레이어를 가지고 있다. 하나의 디코더 레이어는 Self-attention, Feed-forward Network, Layer Normalization, Residual. Self-attention로 구분된다. Query는 현재 주어진 단어와 관련이 있고 Key와 Value는 전체 문맥의 흐름을 나타낸다. GPT-2는 어텐션 가중치를 H개의 열로 나누는 멀티헤드 어텐션을 사용한다. Feed-forward Network은 두 개의 FC Layers와 GELU 활성화 함수로 이루어져 있다. Layer Normalization와 Residual은 fine-tunning 하기 위함이다.
Summarization은 전체 Context를 인풋으로 받기 때문에 디코더의 인풋 차원이 $n \times emb$ 이다. n은 context의 토큰 길이(갯수)이다. 참고로 1.5B 모델의 $emb = 1600$이다. 임베딩 벡터는 디코더로 fed 되는데 가중치 행렬 사이즈가 $emb \times emb$ 거나 더 크며 아웃풋 행렬은 초기 디멘션과 같은 $n \times emb$ 이다. 아웃풋 행렬의 마지막 행만 LM head에서 처리되고 첫번째 토큰이 생성된다.
Key와 Value 행렬도 요약 단계에서 생성된다. 이전에 생성된 토큰이 디코더에 들어가므로 인풋 디멘션이 $1 \times emb$ 이다. 토큰 생성은 이전의 문맥에 따라 결정되므로 새로운 context를 Key와 Value 행렬의 행에 appending 함으로써 row demension을 1씩 늘린다.
B. Parallelism in Deep Learning
Data Parallelism
Data Parallelism은 batch를 여러개의 Worker에 분산시키는 방법이다. 각 Worker는 batch data를 가지고 개인적으로 연산을 수행한다. 추론에는 사용자의 요청이 반영된 싱글 사이즈의 batch나 batch가 아닌 인풋이 사용되기 때문에 적합하지 않다.
Model Parallelism
Model Parallelism은 모델 파라미터를 여러 Worker로 나눈 후 동시에 프로세스한다. 각 worker에 할당되는 양이 줄어들기 때문에 GPT-2나 BERT 같은 거대 모델에 적합하다. 가장 많이 사용되는 scheme은 pipelined parallelism과 intra-layer parallelism이다. 전자의 경우 하나의 Worker만 operation을 수행하고 결과를 다른 operation을 수행하는 worker로 넘긴다. 전체 과정은 높은 throughput을 위해 파이프라인 되지만 latency는 줄어들지 않는다. 후자는 행렬 곱처럼 병렬 처리가 가능한 연산들을 여러 장치로 나눔으로써 실행 시간이 상당히 줄어든다. 반면 전체 아웃풋을 필요로 하는 연산이 나오면 그 전에 synchronization이 필요하다.
III. Motivation
A. Sequential Characteristic
생성 단계의 Sequential Process는 병렬화가 어렵고 연산이 GPU의 모든 거대 연산 유닛을 이용할만큼 intensive 하지 않아서 상당한 underutilization이 발생한다. 아래 그림은 Output Size가 평균 75.45 ms 정도로 latency를 크게 증가시키는 것을 보여준다. 반면 Input Size는 평균 0.02ms 정도 밖에 증가시키지 않았다.
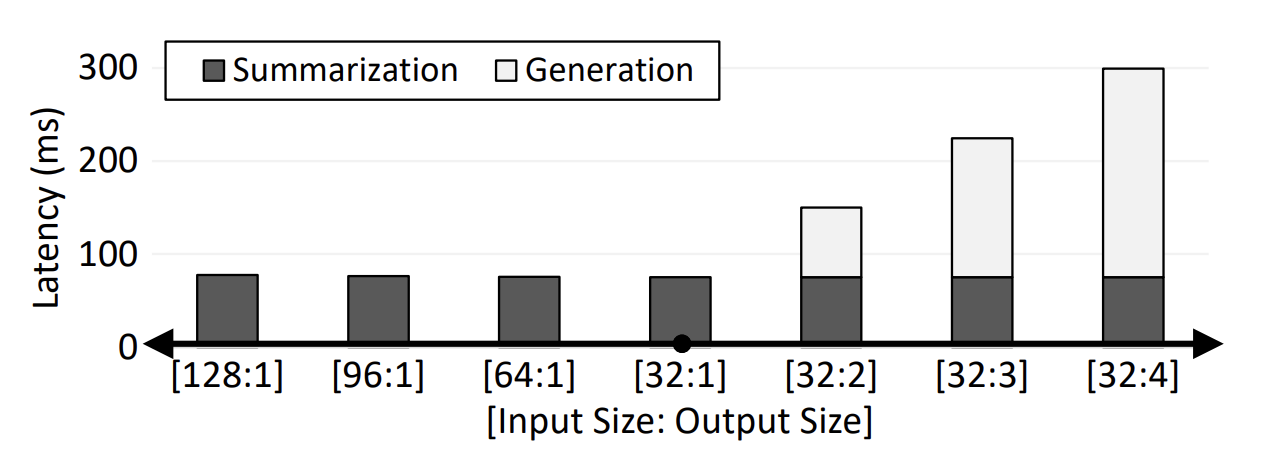
Batch size가 GPT-2 모델의 latency와 throughput에 미치는 영향도 조사하였다. 다양한 사용자의 입력을 배치 처리하는 경우, 사용자로부터 입력을 수집하는데 걸리는 시간으로 인해 latency가 증가한다. 결과적으로 현재 데이터 센터들은 입력을 완전히 수집하지 않고 모델을 실행하는 것을 선호한다. 이 경우 주어진 배치에서 채워지지 않은 인풋 수에 따라 Utilization이 선형적으로 감소하므로, 적은 latency로 싱글 인풋 토큰을 처리할 수 있는 최적화된 datapath가 필요하다.
B. End-to-End Acceleration
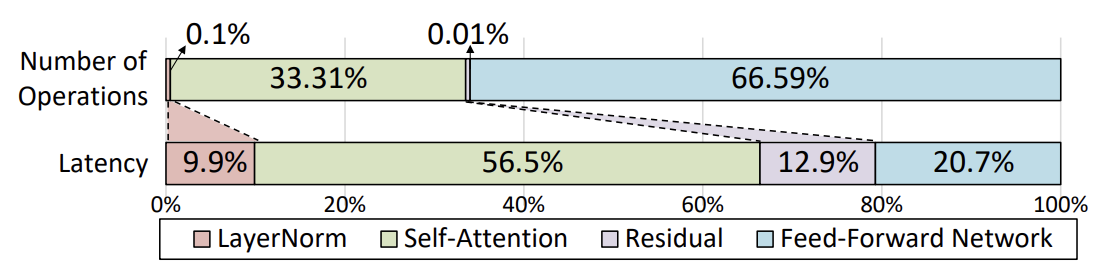
대부분의 연구들은 latency의 대부분을 차지하는 어텐션이나 FFN만 포함시켰다. GPT-2를 처음부터 end-to-end로 실행하기 위해서는 나머지 프로세스들도 호스트에 의해 완성되어야 하는데 모델이 디코더 층을 반복적으로 실행하기 때문에 호스트와 가속기 사이에 데이터 전송이 과도해져서 쉽게 bottleneck으로 이어질 수 있다.
아래 그림은 Layer Normalization과 Residual에 사용된 연산의 비율이 전체의 0.11%에 불과함에도 시간은 22.8%를 차지한다는 것을 보여준다. 그러므로 GPT-2에 최적화된 대체 가속기가 필요하다.
C. Parallel Computing
GPT-2는 대량 연산을 요구하므로, 거대 모델을 여러개의 노드로 나누어 병렬 처리 하는 것이 바람직하다. 병렬 연산을 최소한의 latency 증가로 극대화 할 수 있는 Model Parallelism와 Efficient Network를 채택하는 다중 장치 시스템이 필요하다.
IV. DFX Architecture
A. Architecture Overview
DFX는 듀얼 소켓 CPU와 여러개의 FPGA들로 이루어진 서버 어플라이언스 아키텍쳐이다. 하나의 CPU와 4개의 FPGA로 구성된 클러스터가 독립적인 연산을 수행한다. 각 FPGA가 하나의 연산 코어를 갖고 있어서 클러스터 마다 4개의 코어를 갖는다. FPGA 들은 16 GB/s로 데이터를 전송할 수 있는 PCIe Gen3 Subsystem으로 호스트 CPU와 연결되어 있다. FPGA 간 통신은 100 Gb/s QSFP transceiver로 이뤄진다. 각 FPGA가 두 개의 QSFP 포트들로 한정되어 있어서 ring network가 선택되었다.
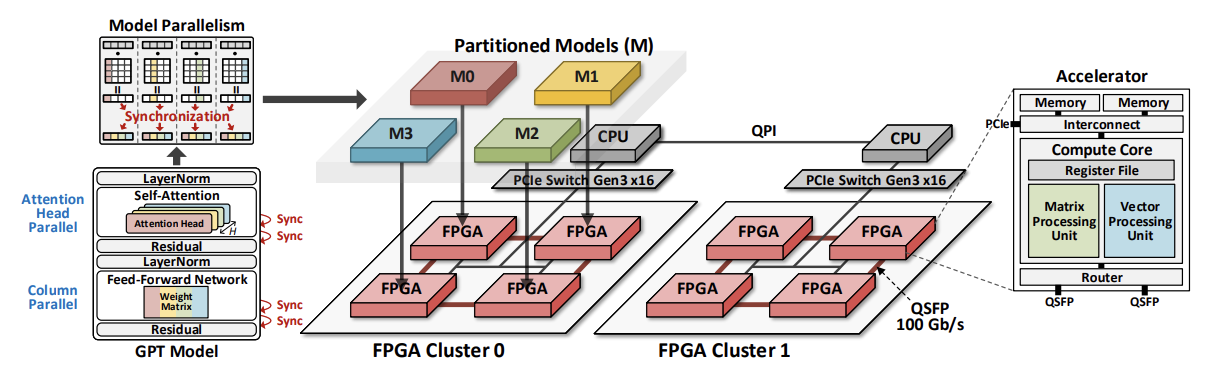
B. Homogeneous Multi-FPGA Cluster
Intra-Layer Parallelism을 적용했다. 최소한의 Synchronization 오버헤드로 latency를 줄이기 위해 특정 Intra-Layer 분할 기법이 사용된다. Pipelining은 높은 latency를 발생시키는데, 그 이유는 모든 worker 들이 단일 인풋을 위해 일하기 때문이다. 게다가 만약 텍스트 생성처럼 최종 아웃풋 결과가 다음 인풋이 되는 경우 두 scheme 간 latency 차이가 디코더 갯수에 따라 선형으로 증가할 것이다.
아래 그림을 보면, 멀티 헤드 어텐션을 위해서 가중치 행렬이 헤드 마다 나눠지고, FC layer를 위한 가중치 행렬이 column-wise 하게 나뉘어서 FPGA가 개인적으로 일할 수 있게 된다. 나눠진 행렬들은 FPGA의 메모리에 저장되고, 각 코어는 동일한 연산을 나눠진 모델 파라미터들에 대해 병렬적으로 실행한다. 각 코어는 Subvector에 해당하는 최종 결과를 얻고, 각 Subvector 들은 Synchronization을 위해 ring network를 통해 다른 FPGA로 순환된다. Synchronization이 끝나면 각 코어들은 완전한 vector를 얻게 되어 다음 벡터 연산을 진행하게 된다. 전반적으로 이 동기화가 셀프 어텐션과 Feed-forward Network 중간과 이후에 한번씩 필요하여 decoder layer 마다 총 4번이 필요하다.
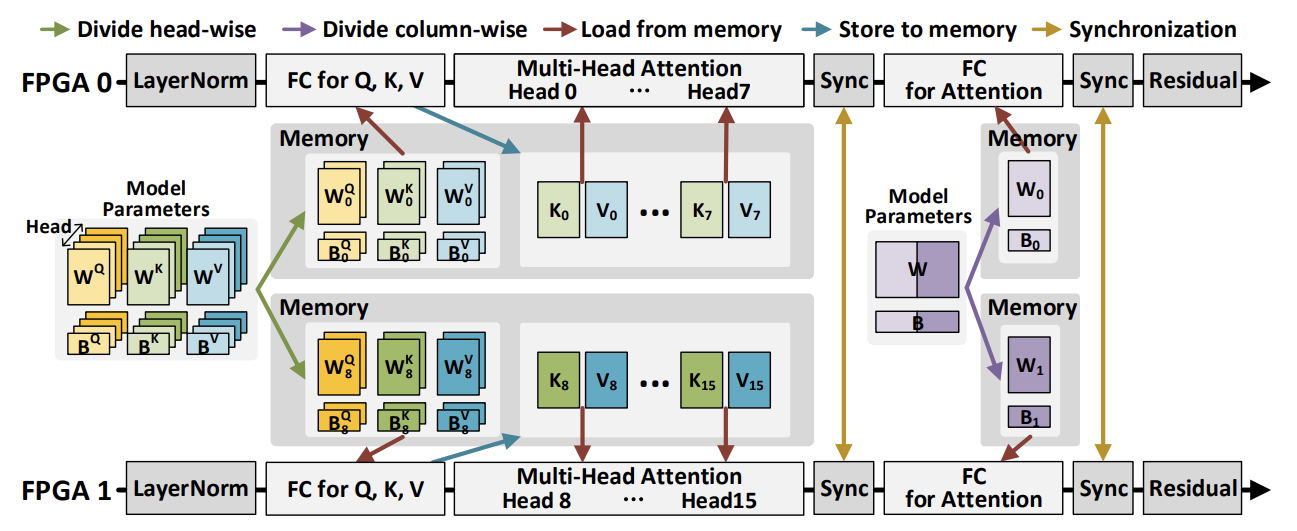
Memory Mapping
FPGA는 8 GB HBM과 32GB DDR를 장착하여 이론적으로 최대 Bandwidth가 각각 460 GB/s와 38 GB/s이다. 가중치 행렬은 HBM에 저장된다. 반면, 인풋/아웃풋 토큰, 바이어스 벡터, 다른 모델 파라미터들은 몇 iteration에 한 번 이나 전체 decoder 단계에서 한 번 접근되기 때문에 DDR에 저장된다. DFX는 FP16 모델 파라미터를 사용해서 추론 정확도를 유지한다.
C. Instruction Set Architecture
DFX는 커스텀한 ISA를 갖고 있어서 어텐션에만 초점을 맞춘 이전의 NLP 가속기들과 달리 GPT-2 추론을 end-to-end로 서포트한다.
Instruction Set
DFX ISA에는 Compute, DMA, Router의 3가지 명령어 타입이 있다. Compute은 메인 프로세싱 유닛을 처리하기 위함이고 (type, src1, src2, dst)와 source나 destination이 off-chip memory에 있는지 on-chip memory에 있는지 결정하기 위한 추가 bit가 존재한다. DMA와 Router 명령어는 주어진 전송 사이즈에 맞게 데이터를 주고 받을 수 있도록 컨트롤하기 위함이다. (type, src, dst, xfer_size) 형식으로 생겼다.
각 명령어 타입은 Instruction Chaining을 통해서 dependent한 명령어들은 최소한의 stalling으로 실행된다. Independent한 명령어들은 병렬적으로 처리된다. 예를 들어, compute는 데이터를 가공하고, DMA는 데이터를 fetch 하고, router는 동기화를 위해 peer device에서 데이터를 가져와서 buffer를 채운다.

Compute Instructions
Compute instructions는 코어 명령어 세트의 대부분을 차지하며 Matrix Instruction와 Vector Instruction로 나눠진다.
Matrix Instructions는 행렬-벡터 곱과 GELU나 reduce max 같은 추가적인 함수를 실행하기 위함이다. 행렬은 tiles에 로드되고 벡터들은 portions에 로드된다.
-
Conv1D: $Ax+b$ 는 Query, Key, Value 행렬 생성과 Feed-forward Network에 사용된다. 이 명령어에서 가중치 행렬 A와 인풋 벡터 x, 바이어스 벡터 b가 필요하다. Conv1D는 convolutional한 면을 가지고 있는데, 그 이유는 인풋 사이즈가 최대 인풋 사이즈보다 커지면 연산이 sliding window로 수행되기 때문이다.
-
MaskedMM: $Ax$의 형태로 Score matrix로 알려진 $Query \times Key^T$를 계산한다. Masking operation은 score 행렬의 upper diagonal elements에 음의 무한대 값을 부여해서 현재 토큰이 미래 contexts의 영향을 받지 않도록 한다. Softmax와의 combination으로 MaskedMM은 lower triangular matrix를 만들고 각 행의 최댓값을 반환한다.
-
MM: MaskedMM에서 Masking을 뺀 것이다. LM head에서 logit을 계산하는데 사용된다. Logit은 아웃풋 임베딩 벡터를 토큰 ID로 변환하고 어텐션 레이어에서 Score x Value를 계산하는 데 사용된다.
Vector Instructions는 load, store과 더불어 벡터-벡터 연산과 벡터-스칼라 연산을 실행한다. add, sub, mul, accum, recip_sqrt, recip, exp 같은 기본 연산도 수행한다. 따라서 LayerNorm과 Softmax 같은 high-level 연산들은 여러 개의 vector instructions들로 실행된다.
- LayerNorm: $\mu$와 $\sigma$ 는 각각 평균과 표준편차를 나타낸다. $\gamma$와 $\beta$는 weight와 bias 벡터를 나타낸다. 평균 계산에는 accum과 mul이 필요하고, 표준편차 계산에는 recip_sqrt가 추가로 필요하다. 그 후 sub, mul, add를 통해 LayerNorm을 계산한다. 파라미터들은 load를 통해 reg file로 fetch 된다.
- Softmax: j는 행의 원소 갯수를 나타낸다. 이 연산은 exp, add, accum과 같은 기본적인 벡터 연산으로 수행될 수 있다. Summation은 LayerNorm에서 평균을 계산하는 것과 비슷하다. 나누기는 recip과 mul로 대체된다.
V. Microarchitecture
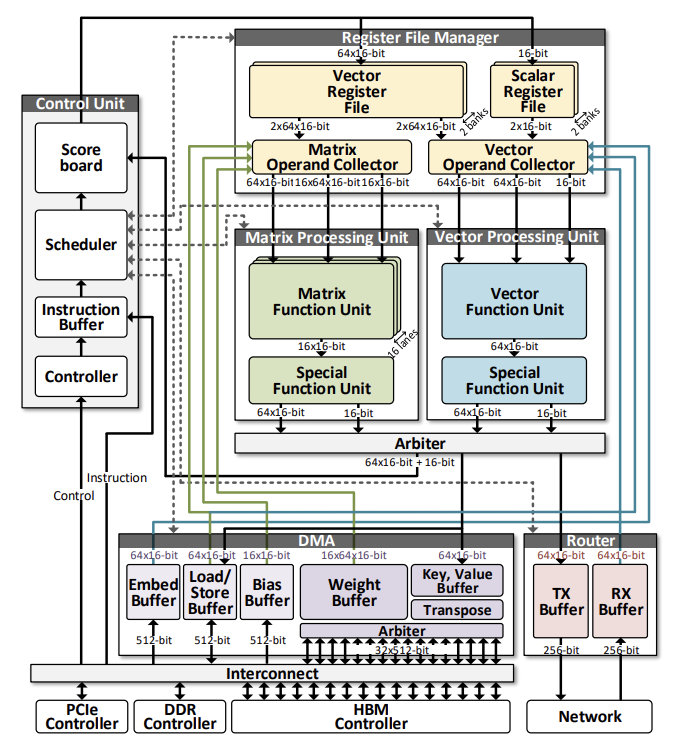
A. Control Unit
각 모듈의 상태를 track하고 어떤 모듈을 쓸지 arbitrating 함으로써 데이터의 전반적인 흐름을 제어한다. Controller, Scheduler, Scoreboard로 구성되어있다.
Controller의 주된 역할은 호스트로부터 Start Signal와 System Configuration을 받는 것이다. System Configuration은 코어 ID, 코어의 수, 디코더 layer 개수, 토큰 개수 등을 포함한다. 각 layer마다 HBM의 다른 부분이 사용되어야 하므로 layer 개수는 DMA가 접근할 주소를 지정한다. 토큰 개수는 MaskedMM에서 어떤 부분을 mask 할지 결정한다. GPT-2 연산이 끝나면 호스트에게 done signal을 보낸다.
Scheduler는 컨트롤러로부터 Decoded System Configuration을 전달받고 Instruction Buffer로부터 Instruction을 받는다. Scheduler는 여러 개의 FSM(Finite State Machine)으로 DMA, Processing Unit, Register File, Router 등의 상태를 체크하고 Instruction을 run 할지 wait 할지 결정한다. 선택된 Instruction은 Scoreboard로 보내져서 실행되고 있는 Instruction 과의 Dependency를 확인한다.
Scoreboard Chaining Method에 기반해서 Dependency Check를 하는 레지스터 파일이다. Instruction이 Data Hazard를 발생시킬 수 있기 때문에 Source와 Destination 주소를 계속 모니터한다. RAM을 이용하는데, Execution 일 때는 stale bit, Writeback 일 때는 valid bit으로 마킹한다. Source와 Destination이 겹치는 경우 Stall 한다.
B. Direct Memory Access
Read와 Write의 Interface를 포함하는 DMA는 High Bandwidth로 전송되는 데이터에서 중요한 역할을 한다. HBM의 Bandwidth를 최대화 하기 위해서 DMA의 R/W 인터페이스는 32개의 모든 HBM 채널과 연결되어 있고, 단일 채널이 512 bits, 200MHz라 총 $32 \times 512$ bits per cycle이 된다. DMA는 Tiled Weights, Key, Value를 행렬 연산에 최적화된 형태로 HBM에 저장하거나 로드한다. Value는 transposed 되어야 하므로 DMA 안에 transpose 유닛이 들어가있다. HBM과 함께 DDR도 접근할 수 있다. 인풋 토큰, 바이어스, WTE, WPE는 DDR에서 읽어진 뒤 대응하는 DMA 안의 buffer로 전송된다. 최종 아웃풋 토큰도 DMA에서 DDR로 써진다. Input Batching을 안하기 때문에 Weights와 Biases는 재사용 될 수 없어서 DMA에 buffered 된다. 그리고 Processing Units로 Streamed 되어 연산된다.
Tiling Scheme
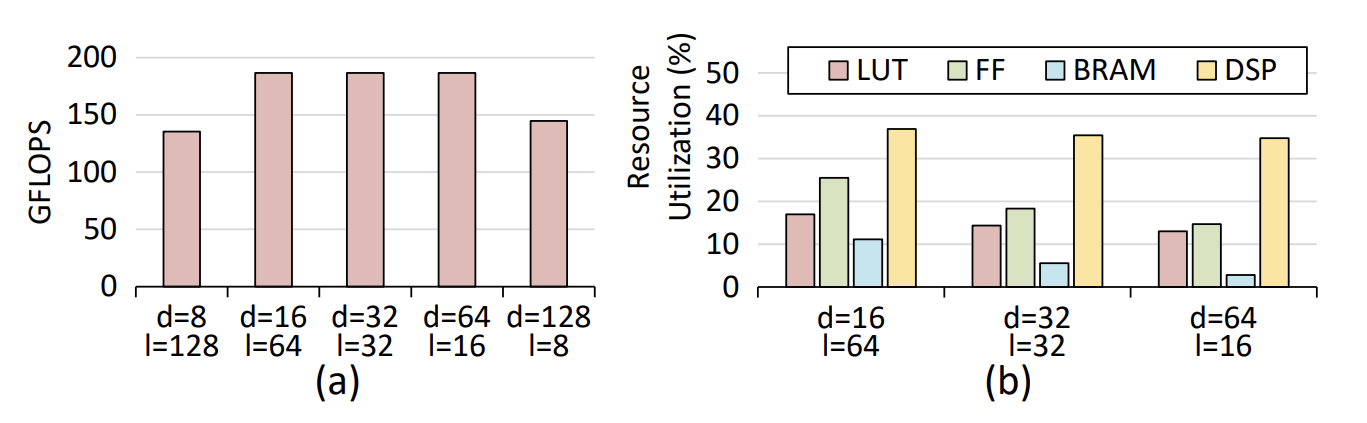
DFX는 Summarize 단계에서의 성능을 유지하면서 Generation 단계에서 연산 수와 throughput을 최대화하는 최적화된 tiling scheme을 사용한다. Generation 단계에서 단일 토큰을 처리하기 위해 거대한 양의 Weights를 HBM으로부터 $32 \times 512$ bits per cycle로 읽어들인다. 차원은 $d \times l \times BW$ 로 조정될 수 있는데, d는 tile dimension, l은 number of lanes, BW는 data bandwidth를 나타낸다. Number of lanes는 행렬 연산 유닛에서 병렬적으로 계산할 수 있는 column의 수이다. DFX는 FP16을 이용하므로 BW는 16이다. $emb \times emb$ 사이즈의 Weight를 로딩할 수 있는 최적의 d와 l 값을 찾는다. 또한, 행렬-벡터 곱의 순서를 translate하는 효과적인 로딩 방향을 찾는다. Design Space Exploration을 통해 (d, l) = (64, 16)라는 최적의 값을 얻었다.
수평 방향으로 타일을 채우면 Input Reuse를 최대화하지만 부분합을 저장하기 위한 상당 수의 버퍼를 필요로 한다. 수직 방향은 버퍼의 수를 하나로 줄이지만, Input Reuse를 없앤다. 따라서 지그재그 방향의 접근으로 하드웨어 자원과 데이터 재사용 사이의 균형을 맞춘다.
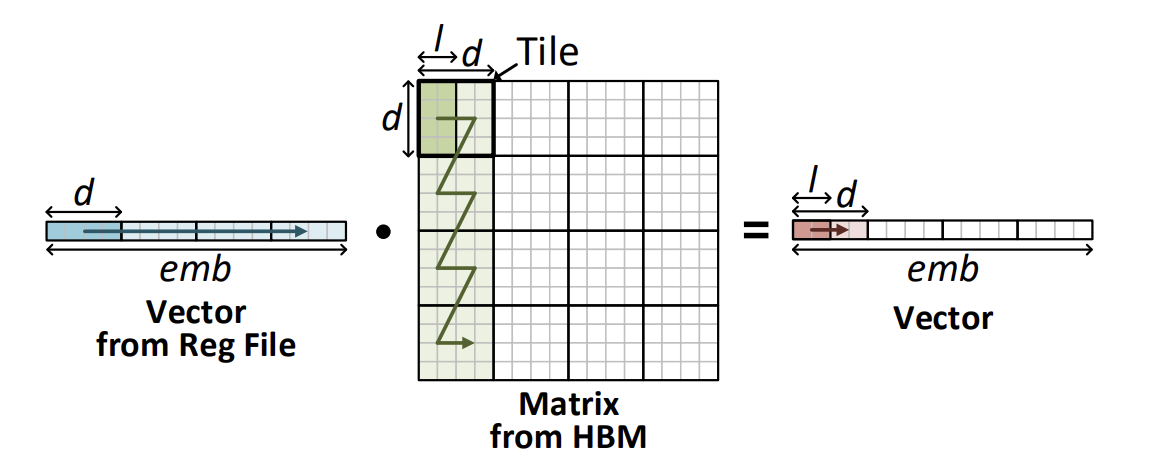
Transpose Scheme
어텐션에서 Key는 transposed 되어야한다. 이 모델에서는 HBM으로부터 읽기가 Column-wise이고 쓰기는 Row-wise 이므로 Value가 Transposed 되어야 한다. 따라서 중간 행렬이 DMA로 로드 될 때 디폴트로 Transposed 되어야한다. 이 문제를 해결하기 위해 DFX는 Value 행렬의 부분 행렬이 Off-chip memory에 Read 될 때가 아닌 Write 할 때 Transpose를 한다. DFX instruction을 재배열해서 Value가 Query, Key보다 먼저 계산되게 함으로써 Value가 Transpose 되기에 충분한 시간을 제공한다.
C. Processing Units
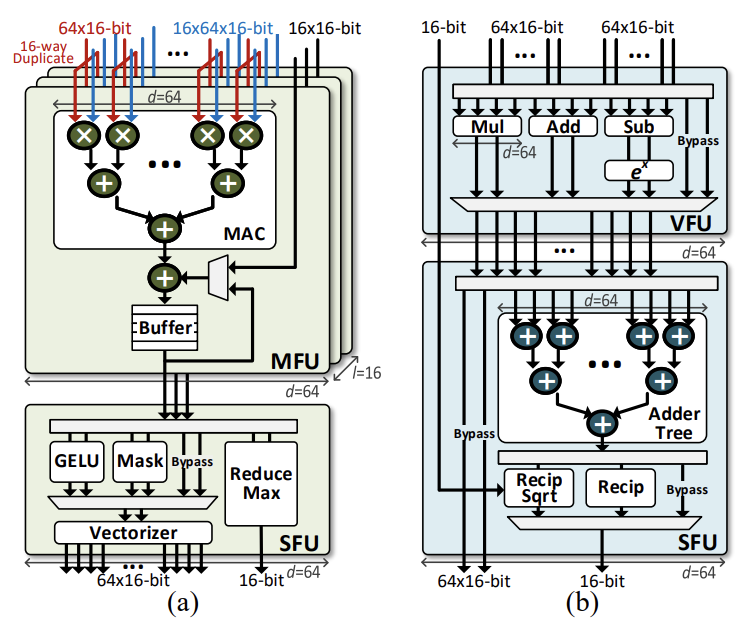
DFX 코어는 두 개의 Processing Units을 가지고 있다. 하나는 Matrix Processing Unit (MPU)이고, 다른 하나는 Vector Processing Unit (VPU)이다. 두 PU는 네 개의 Main Functional Units, Matrix Function Unit, Vector Function Unit, Special Function Unit 으로 구성되어 있고 모두 FP16다. Functional Units은 파이프라인으로 구성되어 Throughput을 최대화하고 Bypasses를 구현한다.
Matrix Function Unit
주된 작업은 행렬-벡터 곱이다. MFU는 트리 기반의 Multiplier-accumulators를 갖고 있어서 d차원의 벡터들을 인풋으로 받는다. Unit은 l lanes로 구성되어 있다. 인풋은 lane마다 동일하지만 l개의 다른 가중치 행렬의 column에서 온 multiplicands가 입력된다. 따라서 $d \times l$ 개의 곱하기가 병렬적으로 처리된다. 각 lane에서 나온 곱은 깊이가 log(d)인 트리로 들어가서 더해진다. FP16 multiplier와 adder은 각각 하나의 DSP와 두개의 DSP로 매핑된다. Multiplier는 6 cycle, adder는 11 cycle이 걸린다. MFU는 총 $3 \times (d \times l)$ 개의 DSP를 사용한다.
Vector Function Unit
Element-wise vector operations을 지원하는 ALU이다. MFU와 비슷하게 DSP가 사용되며 덧셈, 뺄셈, 곱셈, 제곱 연산은 각각 11, 11, 6, 4 cycle이 걸린다. 제곱 연산은 두 개의 DSP를 이용하고 나머지는 하나를 이용한다. 모든 연산이 하나의 ALU 연산으로 완료되므로, Synchronization 없이 가장 짧은 사이클이 걸린다. 추가적으로 VFU는 bypass를 지원해서 불필요한 사이클을 줄인다. 예를 들어 load, store는 어떠한 computational cycle도 필요로 하지 않으므로 EX 단계를 스킵하고 바로 I/O 포트에 연결해서 1 cycle 밖에 걸리지 않는다. Data Hazard는 Scoreboard에서 처리된다.
Special Function Units
Nonlinear functions를 다룬다. MFU와 VFU의 아웃풋은 SPU_M와 SFU_V로 각각 passed 되고, 최적의 하드웨어 Utilization을 위해 DSP, Combinational logic, Lookup Table Method를 사용한다.
-
SFU_M은 행렬-벡터 연산을 책임지며 Masking, GELU, Vectorization, Reduce Max 같은 과정에서 사용된다. Masking unit은 Tile 정보에 따라 Lower Triangular Matrix를 만들며 아웃풋 행렬의 Upper Diagonal Matrix는 음의 무한대에 가장 가까운 수로 나타내진다. 어텐션 헤드로 나눌 때 필요한 나누기는 곱셈으로 대신한다. GELU를 지원하기 위해 Lookup Table로 Linear Approximation을 한다. 2048개의 인풋을 샘플링해서 MSE가 FP16에서 0이 되도록 하고 [-8. 8]을 범위로 잡았다. Vectorizer는 Asymmetric Buffer를 사용해서 아웃풋을 Concatenate 한다. Reduce Max는 Parallel Tree of Comparators로 벡터의 최댓값을 찾는다.
-
SFU_V는 VFU 다음에 오는 벡터 연산을 책임진다. 이 계산들은 누적, 스칼라 역수, 곱셈, 덧셈, 역제곱근 등을 지원한다. VFU는 벡터 출력만을 요구하는 명령어를 지원하므로 Adder Tree는 SFU에 위치해있다. 나머지 기능들은 DSP에 의해 제공된다.
Matrix Operand Collector
IV-C에서 언급한 것처럼 Matrix Microcode를 생성하여 호스트로부터 전달되는 명령어의 양을 줄인다. Matrix Operand Collector는 Microcodes와 인풋 벡터, 가중치 행렬, 바이어스 벡터 등을 MPU에 보낸다. Vector RF로부터 하나의 인풋을 읽으면서 DMA Buffer로부터 가중치와 바이어스를 가져온다. Tiling 순서를 세면서 대응하는 인풋과 아웃풋을 MPU에 할당한다. 동일한 인풋 벡터이 Broadcast 되는 반면 다른 가중치와 바이어스들이 각 lane에 분배된다. 추가로 Double Buffer가 모든 Operands에 사용되어 latency를 줄이고 높은 throughput을 얻는다.
Vector Operand Collector
Microcodes를 생성해서 VPU가 벡터 명령어를 실행하도록 한다. VPU는 다양한 operand 유형이 필요하므로 Vector Operand Collector는 벡터 레지스터 파일와 스칼라 레지스터 파일 모두를 읽을 수 있다. DMA와 Network Router Buffer도 접근 가능해서 load, store, synchronization 등을 수행할 수 있다.
E. Router
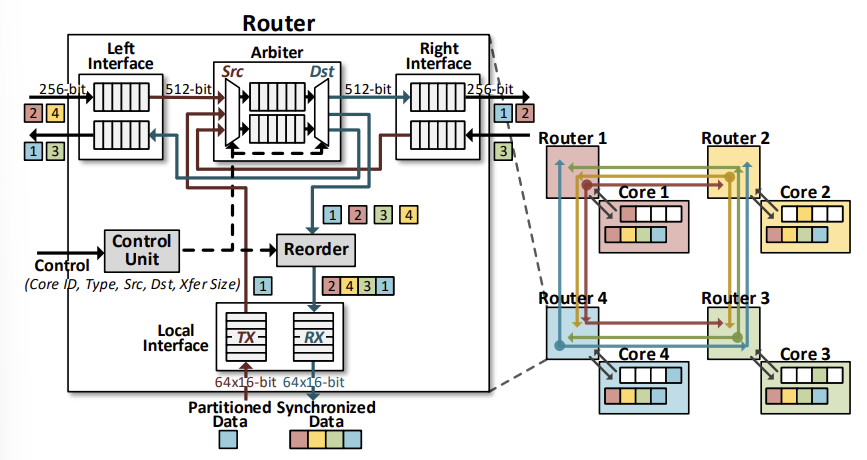
Multi-FPGA의 각 코어는 Ring Network에 있는 다른 코어들의 레지스터 파일 안에 있는 데이터를 동기화하기 위해 router를 사용한다. 라우터는 $64 \times 16$ bit 데이터를 전달해서 프로세싱 유닛으로부터 Output Vector를 Fetch하고 다른 장치로 넘겨준다. 라우터는 컨트롤 유닛이 있어서 어떤 코어와 통신할지 나타내고 버퍼로 주고 받은 벡터들을 보관하며, 각 코어에서 데이터 순서가 동일하게 유지되도록 코어 ID를 Reorder 하는 모듈이 있다.
셀프 어텐션과 피드 포워드 네트워크에서 Conv1D 명령어를 실행한 후에 동기화가 필요한 이유는 모델 병렬 처리로 인해 각 코어가 출력 행렬의 일부만을 계산하게 하는데, 다음 작업인 Layer Normalization이나 Residual은 전체 행을 필요로 하기 때문이다.
네트워크의 P2P 통신은 Aurora 64b/66b IP를 사용한다. Aurora IP는 높은 속도의 Serial 통신을 위해 가벼운 link-layer 프로토콜을 사용한다. 프로토콜은 64b/66b 인코딩을 사용하는데 3%의 전송 오버헤드로 적은 비용이 든다.
용어 정리
-
FPGA는 프로그래밍이 가능한 반도체 장치로 많은 게이트와 논리 블록을 포함하여 다양한 하드웨어 기능을 구현하도록 연결할 수 있다. Multi-FPGA는 말 그대로 여러 개의 FPGA를 동시에 사용하는 시스템을 말한다.
-
Batch 처리는 데이터 센터가 다향한 사용자의 입력을 하나의 큰 데이터 덩어리로 처리한다는 것을 의미한다. 그렇기 때문에 데이터 수집과 처리에 필요한 시간이 달라질 수 있고, 이는 전체 시스템의 대기 시간과 처리량에 영향을 미칠 수 있다.
-
멀티 헤드 어텐션은 전체 모델에서 동일한 입력에 대해 여러 어텐션 헤드가 동시에 동작한다. 각 헤드는 입력 데이터의 다른 특성을 포착하여 처리할 수 있게 한다.
2024/06/19